知识问答
知识问答是通过检索增强生成(RAG)技术,从数据源中精准提取信息并生成答案的智能交互方式。可用于企业客服、医疗辅助、IT支持等领域。
约束限制
- 知识问答需要先对数据源库进行知识加工生成知识库,否则无法问答。
- 用户问答时,RAG可使用的历史记录范围为最近1次问答内容。
- RAG不提供敏感词风控检测能力,开发者需要自行对用户输入内容和RAG返回内容进行敏感词风控检测。
- 开发者应选择上下文长度至少应该为30k Tokens的LLM,如Qwen2.5-7B-32K、Mistral-7B-Instruct-v0.2、Llama-3.1-8B等。否则可能会因大模型上下文长度超限而导致知识问答失败。
- LLM由开发者自行选择,问答支持的语言受选择的LLM影响。
接口说明
![]()
接口需在页面或自定义组件生命周期内调用。
RAG关键接口如下表所示,具体API说明详见API参考。除接口外,还可以通过配置文件进行深度定制RAG,详见RAG配置。
| 接口名 | 描述 |
|---|---|
| abstract streamChat(query: string, callback: Callback<LLMStreamAnswer>): Promise<LLMRequestInfo> | 继承ChatLLM类实现大模型客户端时需要实现的函数。RAG在检索前的问题预处理、检索后的回答生成时,会调用这个函数与大语言模型交互。 |
| createRagSession(context: common.Context, config: Config): Promise<RagSession> | 获得一个会话用于进行知识问答。不支持多线程调用。 |
| streamRun(question: string, config: RunConfig, callback: AsyncCallback<Stream>): Promise<number> | 知识问答接口,传入问题以及问答配置项。当RAG生成问题结果时,触发callback回调函数来流式传递数据。支持的长度为1000个字符内(UTF-8下一个汉字占3个字符)。不支持多线程调用。 |
开发准备
-
申请网络权限。streamChat中需要开发者实现与LLM交互的功能,因此需要为应用申请网络权限。
// module.json5中配置"requestPermissions"字段// src/main/module.json5"requestPermissions": [{"name": "ohos.permission.INTERNET"}], -
完成知识加工配置。请参考知识加工。
开发步骤
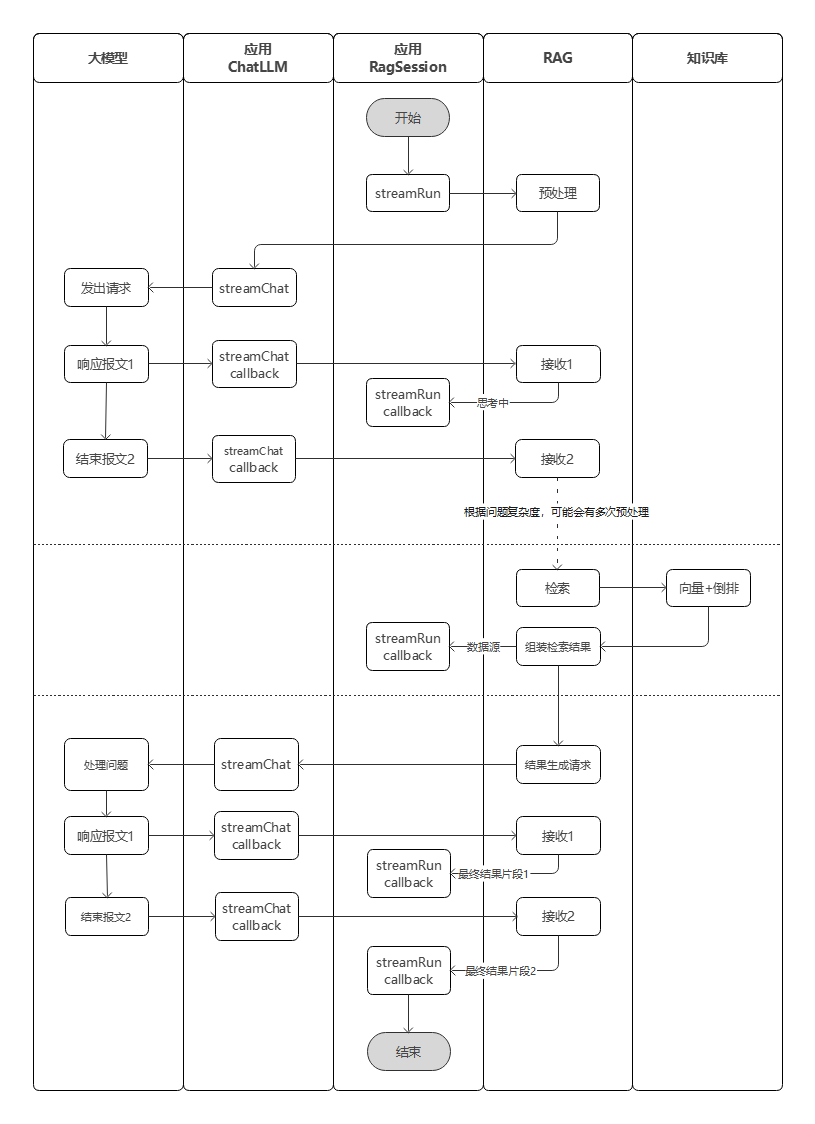
下面仅对关键步骤关键代码进行片段式说明,省略了很多非核心代码,如果需要查看完整功能示例代码,请参考示例代码。应用的一次流式问答过程,和RagSession、ChatLLM、知识库的交互流程,可参考流式问答调用流程图。
-
导入@kit.DataAugmentationKit模块,其余依赖需要开发者按需添加。
import { rag } from '@kit.DataAugmentationKit'; -
创建http工具类,用以和大模型交互,用户也可选择webSocket(可参考Network Kit)或者其他方式与大模型交互。本示例选用了ModelArts平台的qwen3-235b-a22b模型作为示例,开发者使用时需根据实际情况选择合适大模型。示例代码包括如下三个环节:
- 拼装和大模型交互的请求报文,推荐为流式交互,以获得更好用户体验。
- 注册大模型的数据接收及输出结束的回调函数,以达到流式访问大模型的效果。
- 初始化大模型以及向大模型发送请求。
import { BusinessError } from '@kit.BasicServicesKit';import { http } from '@kit.NetworkKit';import { hilog } from '@kit.PerformanceAnalysisKit';const TAG = 'HttpUtils';class HttpUtils {httpRequest?: http.HttpRequest;url: string = 'https://api.modelarts-maas.com/v1/chat/completions'; // 开发者需要根据选择的大模型对应修改url以及下面的modelisFinished: boolean = false;initOption(question: string) {let option: http.HttpRequestOptions = {// 请求方式method: http.RequestMethod.POST,// 请求头header: {'Content-Type': 'application/json',// API-KEY from Model'Authorization': `Bearer ****replace your API key in here****`},// 请求体extraData: {'stream': true,'temperature': 0.1,'max_tokens': 1000,'frequency_penalty': 1,'model': 'qwen3-32b','top_p': 0.1,'presence_penalty': -1,'messages': JSON.parse(question),"chat_template_kwargs": {// 关闭思考中数据"enable_thinking": false}}};return option;}async requestInStream(question: string) { // 拼装流式请求的option并发起流式请求if (!this.httpRequest) {this.httpRequest = http.createHttp();}this.httpRequest?.requestInStream(this.url, this.initOption(question)).catch((err: BusinessError) => {hilog.error(0, TAG, 'Failed to request. Cause: %{public}s', JSON.stringify(err));});this.isFinished = false;}on(callback: Callback<ArrayBuffer>) { // 注册数据接受、数据结束的监听if (!this.httpRequest) {this.httpRequest = http.createHttp();}this.httpRequest.on('dataReceive', callback);}cancel() {this.httpRequest?.off('dataReceive');this.httpRequest?.destroy();this.httpRequest = undefined;}}export default new HttpUtils; -
继承实现ChatLLM类,在此函数中与大模型进行交互,并将大模型返回结果通过callback函数返回给RagSession。
import { rag } from '@kit.DataAugmentationKit';import { hilog } from '@kit.PerformanceAnalysisKit';import { JSON, util } from '@kit.ArkTS';import HttpUtils from './HttpUtils'; // HttpUtils为上一步骤中,在文件HttpUtils.ets文件中实现的HTTP访问工具类const TAG = "MyChatLLM";export default class MyChatLLM extends rag.ChatLLM {async streamChat(query: string, callback: Callback<rag.LLMStreamAnswer>): Promise<rag.LLMRequestInfo> {let ret: rag.LLMRequestStatus = rag.LLMRequestStatus.LLM_SUCCESS;try {let dataCallback = async (data: ArrayBuffer) => { // 收到数据时的回调函数,解析数据并组装LLMStreamAnswer,通过callback回调hilog.debug(0, TAG, 'on callback enter. data length: %{public}d', data.byteLength);// 解析大模型返回报文,逻辑因选择模型而异,此处省略具体解析代码,示例参见完整示例代码const answer = parseLLMResponse(data);if (!answer) {return;}HttpUtils.isFinished = answer.isFinished;callback(answer);hilog.debug(0, 'MyChatLLM', 'Request LLM success. isFinished: %{public}s, data: %{public}s',Number(answer.isFinished).toString(), answer.chunk);};HttpUtils.on(dataCallback);HttpUtils.requestInStream(query);} catch (err) {hilog.error(0, TAG, `Request LLM failed, error code: ${err.code}, error message: ${err.message}`);ret = rag.LLMRequestStatus.LLM_REQUEST_ERROR; // 开发者可判断错误码从而返回其他LLM错误码}return {chatId: 0,status: ret,};}cancel(chatId: number): void {hilog.info(0, TAG, `The request for the large model has been canceled. chatId: ${chatId}`);HttpUtils.cancel();}}function parseLLMResponse(data: ArrayBuffer): rag.LLMStreamAnswer {throw new Error('Function not implemented.'); // 待实现大模型报文解析流程} -
创建Config配置中的属性。下面简要介绍几个主要属性,有关全量配置字段的详细含义,请参见智慧化数据检索中的说明。开发者可以根据自身需求进行选择性配置。
-
RetrievalConfig主要配置知识库的数据库配置。知识加工将会生成向量及倒排两种知识库表。
import { common, UIAbility } from '@kit.AbilityKit';import { rag, retrieval } from '@kit.DataAugmentationKit';import { relationalStore } from '@kit.ArkData';let storeConfigVector: relationalStore.StoreConfig = {name: 'testmail_store_vector.db', // 知识加工后向量数据库文件名,在原数据库名基础上加_vector后缀securityLevel: relationalStore.SecurityLevel.S3,vector: true // 向量数据库应设置该项为true};let storeConfigInvIdx: relationalStore.StoreConfig = {name: 'testmail_store.db', // 知识加工后,倒排数据库即原数据库securityLevel: relationalStore.SecurityLevel.S3,tokenizer: relationalStore.Tokenizer.CUSTOM_TOKENIZER};let context = AppStorage.get<common.UIAbilityContext>('Context') as common.UIAbilityContext;let channelConfigVector: retrieval.ChannelConfig = {channelType: retrieval.ChannelType.VECTOR_DATABASE,context: context,dbConfig: storeConfigVector};let channelConfigInvIdx: retrieval.ChannelConfig = {channelType: retrieval.ChannelType.INVERTED_INDEX_DATABASE,context: context,dbConfig: storeConfigInvIdx};// 最终创建成功的RetrievalConfig数据let retrievalConfig: retrieval.RetrievalConfig = {channelConfigs: [channelConfigInvIdx, channelConfigVector]}; -
RetrievalCondition主要配置检索条件及多路召回之后的排序配置。其中fromClause为查询目标索引名,可按照如下示例代码配置为业务数据库表及知识加工产生的数据库表联合形成的虚拟表;responseColumns为召回的字段集合,范围为fromClause配置的数据库表中的列。关于知识库的数据库表结构可参见:知识加工。
import { retrieval } from '@kit.DataAugmentationKit';let recallConditionInvIdx: retrieval.InvertedIndexRecallCondition = {ftsTableName: 'email_inverted',fromClause: 'email_inverted',primaryKey: ['chunk_id'],// 配置范围为fromClause配置的数据库表中的列,超出范围会导致检索失败。responseColumns: ['reference_id', 'chunk_id', 'chunk_source', 'chunk_text'],deepSize: 500,recallName: 'invertedvectorRecall',};let floatArray = new Float32Array(128).fill(0.1);let vectorQuery: retrieval.VectorQuery = {column: 'repr',value: floatArray,similarityThreshold: 0.1};let recallConditionVector: retrieval.VectorRecallCondition = {vectorQuery: vectorQuery,// 只配置知识库的向量表作为查询目标fromClause: 'email_vector',primaryKey: ['id'],// 配置知识库的向量表中的列作为召回列responseColumns: ['reference_id', 'chunk_id', 'chunk_source', 'repr'],recallName: 'vectorRecall',deepSize: 500};let rerankMethod: retrieval.RerankMethod = {rerankType: retrieval.RerankType.RRF,isSoftmaxNormalized: true,};// 最终创建成功的RetrievalCondition数据let retrievalCondition: retrieval.RetrievalCondition = {rerankMethod: rerankMethod,recallConditions: [recallConditionInvIdx, recallConditionVector],resultCount: 5}; -
完成Config数据的构造。ChatLLM参数则使用步骤3继承实现的ChatLLM的自定义的类的实例。
import { rag } from "@kit.DataAugmentationKit";import MyChatLLM from "./MyChatLlm"; // 来源参考步骤3示例代码let config: rag.Config = {llm: new MyChatLLM(), // 来源参考步骤3示例代码retrievalConfig: retrievalConfig, // 来源参考当前步骤RetrievalConfig代码示例retrievalCondition: retrievalCondition // 来源参考当前步骤RetrievalCondition代码示例}
-
-
创建RagSession。
import { UIAbility } from '@kit.AbilityKit';import { rag } from '@kit.DataAugmentationKit';import { hilog } from '@kit.PerformanceAnalysisKit';import { BusinessError } from '@kit.BasicServicesKit';// 创建RagSession并存入APP上下文中rag.createRagSession(this.context, config).then((data) => { // config来源参考步骤4代码示例AppStorage.setOrCreate<rag.RagSession>('RagSessionObject', data);}).catch((err: BusinessError) => {hilog.error(DOMAIN, 'testTag', `createRagSession failed, code is ${err.code},message is ${err.message}.`);}); -
使用步骤5创建的RagSession的streamRun()函数进行问答。
- answerTypes属性用来指定流式输出的数据类型(StreamType),当前示例代码配置了三种数据类型,所以最终streamRun()函数的callback回调函数将会输出这三种类型的数据。
- streamRun()函数以增量流式的方式输出数据,所以需要开发者自行对结果进行拼接。
import { BusinessError } from '@kit.BasicServicesKit';import { rag } from '@kit.DataAugmentationKit';import hilog from '@ohos.hilog';// 获取创建的RagSessionlet session: rag.RagSession = AppStorage.get<rag.RagSession>('RagSessionObject') as rag.RagSession;let config: rag.RunConfig = {// 指定流式输出的输出类型answerTypes: [rag.StreamType.THOUGHT, rag.StreamType.ANSWER]};let thoughtStr = '';let answerStr = '';let inputStr = '';// 发起提问session.streamRun(inputStr, config, ((err: BusinessError, stream: rag.Stream) => {// 接收答案的callback回调,处理答案信息if (err) {answerStr = `streamRun inner failed. code is ${err.code}, message is ${err.message}`;} else {// 根据不同的数据类型,选择不同的处理方式switch (stream.type) {case rag.StreamType.THOUGHT:thoughtStr += stream.answer.chunk;break;case rag.StreamType.ANSWER:answerStr += stream.answer.chunk;break;case rag.StreamType.REFERENCE:default:hilog.info(0, 'Index', `streamRun msg: ${JSON.stringify(stream)}`);}}})).catch((e: BusinessError) => {answerStr = `streamRun failed. code is ${e.code}, message is ${e.message}`;})
流式问答调用流程图