网络结构搜索训练
网络结构搜索训练请按照如下步骤进行:
- 准备环境(环境准备)。
- 准备数据集(数据集准备)。
- 配置搜索参数(搜索参数配置)。
- 配置开发者接口(TensorFlow开发者自定义接口、PyTorch开发者自定义接口)。
- 搜索和训练网络结构(搜索训练)。
环境准备
Linux环境
-
NASEA策略运行环境的依赖在如下的requirements中:
tensorflow-gpu==2.8ruamel.yaml==0.17.28PyYAML==5.4.1Cython==0.29.35pymoo==0.3.2pathlibmpi4py==3.1.4sklearnopencv-pythonmatplotlibnumpy==1.23.5tqdm==4.43.0protobuf==3.20.3requests==2.31.0Pillow==7.1.2请使用pip或者conda安装上述依赖。

如果仅需要在单机单卡运行工具,可跳过后续步骤。如需要单机多卡环境运行,请继续完成如下步骤。
-
安装并配置Horovod和Open MPI。
-
安装mpi4py。
pip3 install mpi4py -
验证安装。
下载Horovod官方对应的Demo到当前目录。在一台服务器上利用4张加速卡运行如下命令:
horovodrun -np 4 -H localhost:4 python3 tensorflow_mnist.py若正常训练,则Horovod环境部署成功。
数据集准备
开发者根据需要准备数据集或代理数据集:
-
在user_module.py中定义数据集函数,并在该函数中接收scen.yaml传入的数据集路径。
TensorFlow版本中函数名为build_dataset_search,PyTorch版本中函数名为dataset_define。
-
解析数据集,读取图片和标签。根据is_training判断是训练还是评估模式。
- 如果是训练模式,则dataset_dir传入scen.yaml中配置的train_dir目录。
- 如果是评估模式,则dataset_dir传入scen.yaml中配置的val_dir目录。
-
解析对应的数据并返回处理后的数据(具体接口定义参见TensorFlow开发者自定义接口、PyTorch开发者自定义接口)。
搜索参数配置
开发者可配置合适的搜索参数,以达到较优的搜索结果。开发者需自行完成配置文件(可参考"tools_dopt/dopt_tf_py3/demo/nas_ea/ea_cls_imagenet/scen.yaml"),如下示例:
## Network architecture search scenario
scenario:
strategy:
name: NASEA
framework: Tensorflow
batch_size: 128
epochs: 60
constraint:
application_type: "image_classification"
constraint_type: "size"
constraint_value: 11000000
supernet:
input_shape: (224, 224, 3)
data_format: "channels_last"
filters: [64, 64, 128, 128, 256, 256]
strides: [1, 1, 2, 1, 2, 1]
feature_choose: [4, 5]
optimizer:
weights_optimizer:
type: "Adam"
betas: [0.9, 0.999]
learning_rate: 0.0001
dataset:
pre_train_dir: "/tmp/tfrecords"
train_dir: "/tmp/ImageNet_tf/"
val_dir: "/tmp/ImageNet_tf/"
searcher:
generation_num: 100
pop_size: 40
resource:
name: Tensorflow_standalone
gpu_id: 0,1,2,3,4,5,6,7
参数说明如下表所示。
| 参数名称 | 类型 | 取值范围 | 是否必选 | 参数描述 |
|---|---|---|---|---|
| scenario.strategy | N/A | N/A | N/A | N/A |
| name | string | NASEA | 是 | 策略名。 |
| framework | string | TensorFlow、PyTorch | 是 | 训练框架 |
| batch_size | int | N/A | 是 | 数据集的batch_size。 |
| epochs | int | N/A | 是 | 数据集轮询次数。 |
| scenario.strategy.supernet | N/A | N/A | N/A | N/A |
| input_shape | tuple | N/A | 否 | 模型输入shape的CHW或HWC的维度,默认值:(224, 224, 3)。 |
| data_format | string | channels_first/channels_last | 否 | 数据格式,input_shape和data_format取值需要对应,例:"channels_last"。在PyTorch版本中,该参数只支持channels_first选项。 |
| filters | list | N/A | 否 | 搜索骨架每层的cout,与strides对应的列表,格式为[cout, ..., cout],例:[64, 64, 128, 128, 256, 256]。 |
| strides | list | N/A | 否 | 搜索骨架每层使用的stride,例:[1, 1, 2, 1, 2, 1]。 |
| feature_choose | list | N/A | 否 | 需要融合的待搜索层,以逗号分隔,从0开始计数。例:融合第4、6层:[3, 5]。 该参数当前仅适用于TensorFlow版本的检测场景和PyTorch版本的分割场景。 |
| scenario.strategy.constraint | N/A | N/A | N/A | N/A |
| application_type | string | image_classification/object_detection/ semantic_segmentation | 是 | 应用类型,支持分类、检测和分割场景。 |
| constraint_type | string | size/flops/latency | 是 | 模型约束类型。目前“latency”约束仅支持TensorFlow版本的分类场景。 |
| constraint_value | int, float | N/A | 是 | 模型约束取值,整个网络的大小。 |
| processor_version | string | npu_v1 | 否 | 该参数目前仅支持模型约束类型为"latency"的场景。 |
| scenario.strategy.optimizer | N/A | N/A | N/A | N/A |
| scenario.strategy.optimizer.weights_optimizer | N/A | N/A | N/A | N/A |
| type | string | SGD/Momentum/Adam | 否 | 优化器[1],分类检测默认值:"Adam",分割默认值:"Momentum"。在PyTorch版本中,目前仅支持"SGD"和"Adam"两种优化器,分类场景和分割场景的默认优化器为"Adam"。 |
| betas | list | (0, 1) | 否 | 衰减因子,Adam优化器参数,默认值:[0.9, 0.999]。 |
| learning_rate | float | (0, 1) | 否 | 学习率,多GPU时工具会自动翻倍,分类检测默认值:0.0001,分割默认值:0.00001。 |
| momentum | float | (0, 1) | 否 | 动量,Momentum优化器参数,默认值:0.9。该参数目前仅支持TensorFlow版本。 |
| scenario.strategy.dataset | N/A | N/A | N/A | N/A |
| pre_train_dir | string | N/A | 是 | 检测和分割场景为必选项,分类场景无需此字段,预训练数据集路径或预训练生成的ckpt路径(参见注释[2])。 |
| train_dir | string | N/A | 是 | 训练数据集路径。 |
| val_dir | string | N/A | 是 | 验证数据集路径。 |
| scenario.strategy.searcher | N/A | N/A | N/A | N/A |
| generation_num | int | N/A | 否 | 进化算法的代数,例:100。 |
| pop_size | int | N/A | 否 | 进化算法的种群数量,默认值:40。 |
| scenario.resource | N/A | N/A | N/A | N/A |
| name | string | Tensorflow_standalone/ pytorch_standalone | 是 | 资源对象名称。 |
| gpu_id | string | N/A | 是 | 指定使用的gpuID。 - 填写一个gpu id,如0,则使用单机单卡模式进行训练。 - 填写多个gpu id,如0, 1, 2, 3,则使用单机多卡模型进行训练。 |
![]()
[1] 优化器类型支持SGD,Momentum和Adam三种优化器类型。
- SGD优化器,支持learning_rate参数。
- Momentum优化器,支持momentum、learning_rate参数。PyTorch版本目前不支持该优化器。
- Adam优化器,支持betas、learning_rate参数,betas的形式为list,list中索引为0的元素为beta1,索引为1的元素为beta2。
[2] 当没有预训练的ckpt文件时,其取值为预训练数据集的目录路径;当有预训练的ckpt文件时,其取值为ckpt所在的目录路径。
TensorFlow开发者自定义接口
网络结构搜索基于TensorFlow框架进行训练,开发者需要按照如下的接口定义配置模型训练文件。
![]()
仅支持tf.keras实现。
UserModule类
| 类描述 | 函数描述 | 接口定义 |
|---|---|---|
| class UserModule - 定义开发者侧接口。 | 构造函数。 | def init(self, epoch, batch_size) |
此类用于定义搜索过程中的以下几个函数:
-
数据集读取。
函数描述 接口定义 参数描述 返回值 数据集读取函数。 分类场景: def build_dataset_search(self, dataset_dir, is_training) 检测、分割场景: def build_dataset_search(self, dataset_dir, is_training, is_shuffle) dataset_dir:数据集路径。当前is_training为True时传入scen.yaml中配置的train_dir路径,否则传入scen.yaml中配置的val_dir路径。 is_training:训练时为True; 推理时为False。 is_shuffle:数据集是否需要shuffle。提示:在evaluation阶段更新bn时,数据集不需要做shuffle。 - 训练流程 分类、分割场景: dataset: TensorFlow数据集。 data_num: 数据集图片数量。 检测场景: train_generator:训练集生成器。 train_dataset_size:训练集数量。 - 推理流程 分类、分割场景: dataset: TensorFlow数据集。 data_num: 数据集图片数量。 检测场景: val_generator:验证集生成器。 val_dataset:解析json文件后的数据集。 val_dataset_size:验证集数量。 -
学习率更新策略。
函数描述 接口定义 参数描述 返回值 学习率更新策略函数。 def lr_scheduler(self, lr_init, global_step) lr_init:学习率的初始值。 global_step:TensorFlow的global step。 已更新的学习率。 推荐将学习率的初始值设为常数。
-
评估函数。
函数描述 接口定义 参数描述 返回值 评估函数。 def metrics_op(self, inputs, outputs) - 分类、分割场景 inputs:真值标签(ground truth labels)。 outputs:前向推理的结果。 - 检测场景 inputs: [valid_dir, model] valid_dir:验证集路径。 model:网络模型。 outputs: [data_generator, proxy_val_image_ids, data_size] data_generator:数据集生成器。 proxy_val_image_ids:代理验证集图片索引,用于从验证集中挑选出一个子集,以加快评估效率。 data_size:数据集大小。 评估结果。 -
loss计算函数。
函数描述 接口定义 参数描述 返回值 loss计算函数。 def loss_op(self, labels, logits) labels:真值标签(ground truth labels)。 logits:前向推理的结果。 loss值,tensor。
PreNet类
模型中输入层不需要搜索,因此通过固定网络结构的形式定义。
| 类描述 | 函数描述 | 接口定义 | 参数描述 | 返回值 |
|---|---|---|---|---|
| Class **PreNet **- 模型输入层。 | PreNet构造函数。 | def init(self) | N/A。 | N/A。 |
| - | 构建模型的输入结构。 | def call(self, inputs, training=True) | inputs:输入数据。 training:训练时为True; 推理时为False。 | 搜索骨架的输入,tensor。 |
PostNet类
模型中输出层不需要搜索,因此通过固定网络结构的形式定义。
| 类描述 | 函数描述 | 接口定义 | 参数描述 | 返回值 |
|---|---|---|---|---|
| Class PostNet - 模型输出层。 | PostNet构造函数。 | def init(self) | N/A。 | N/A。 |
| - | 构建模型的输入结构。 | def call(self, inputs, training=True) | inputs:搜索骨架的输出。 training:训练时为True; 推理时为False。 | 模型输出,tensor。 |
PyTorch开发者自定义接口
网络结构搜索基于PyTorch框架进行训练,开发者需要按照如下的接口定义配置模型训练文件。
UserModule类
表1 UserModule类
| 类描述 | 函数描述 | 接口定义 |
|---|---|---|
| class UserModule - 定义开发者侧接口 | 构造函数 | def init(self, epoch, batch_size) |
此类用于定义搜索过程中的以下几个函数:
表2 数据集读取
| 函数描述 | 接口定义 | 参数描述 | 返回值 |
|---|---|---|---|
| 数据集读取函数 | def dataset_define(self, dataset_dir, is_training) | dataset_dir:数据集路径,当前is_training为True时传入scen.yaml中配置的train_dir路径,否则传入scen.yaml中配置的val_dir路径。 is_training:训练时为True; 推理时为False。 | PyTorch的torch.utils.data.Dataset对象实例。 |
表3 学习率更新策略
| 函数描述 | 接口定义 | 参数描述 | 返回值 |
|---|---|---|---|
| 学习率更新策略函数 | def scheduler_define(self, optimizer, steps_per_epoch) | optimizer:优化器对象实例。 steps_per_epoch:训练过程中每个epoch的步数。 | PyTorch的lr_scheduler对象实例。 |
表4 评估函数
| 函数描述 | 接口定义 | 参数描述 | 返回值 |
|---|---|---|---|
| 评估函数 | def metrics_func(self, eval_dataloader, eval_function) | - eval_dataloader:PyTorch的Dataloader对象,用于加载验证数据集。 - eval_function:前向推理函数,eval_dataloader中加载的数据输入到该函数中可以得到对应的推理结果。 | 评估结果。 |
表5 loss计算函数
| 函数描述 | 接口定义 | 参数描述 | 返回值 |
|---|---|---|---|
| loss计算函数 | def loss_func(self, labels, logits) | labels:数据的真实标签。 logits:前向推理的结果。 | loss值。 |
PreNet类
模型中输入层不需要搜索,因此通过固定网络结构的形式定义。
| 类描述 | 函数描述 | 接口定义 | 参数描述 | 返回值 |
|---|---|---|---|---|
| Class **PreNet **- 模型输入层。 | PreNet构造函数。 | def init(self) | N/A。 | N/A。 |
| - | 构建模型的输入结构。 | def forward(self, inputs) | inputs:输入数据。 | 搜索骨架的输入,tensor。 |
PostNet类
模型中输出层不需要搜索,因此通过固定网络结构的形式定义。
| 类描述 | 函数描述 | 接口定义 | 参数描述 | 返回值 |
|---|---|---|---|---|
| Class PostNet - 模型输出层。 | PostNet构造函数。 | def init(self) | N/A。 | N/A。 |
| - | 构建模型的输入结构。 | def** forward**(self, inputs) | inputs:搜索骨架的输出,如果开发者在scen.yaml中没有配置feature_choose,那么inputs是一个tensor;如果开发者配置了scen.yaml中的feature_choose参数,那么inputs是一个列表,其内容依次为feature_choose中配置的对应层的输出以及搜索骨架最后一层的输出。 | 模型输出,tensor。 |
搜索训练
主要从以下三个方面介绍工具的训练入口,维测方式以及搜索结果展示。
训练入口
TensorFlow开发者执行python3 tools_dopt/dopt_tf_py3/dopt_so.py -c scen.yaml,即开启搜索训练;PyTorch开发者执行python3 tools_dopt/dopt_pytorch_py3/dopt_so.py -c scen.yaml。针对每种场景都有对应的demo目录入口,详见TensorFlow NASEA网络结构搜索Demo。
![]()
在执行上述命令时,工具将在当前目录下查找user_module.py文件。
维测方式
搜索训练过程可以利用TensorBoard进行观测中间信息,生成的信息文件保存在log_*目录。
-
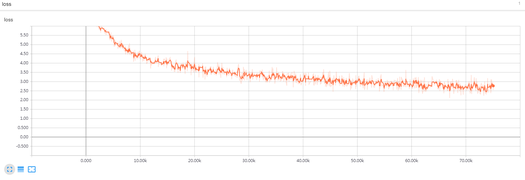
loss-模型精度损失loss曲线
-
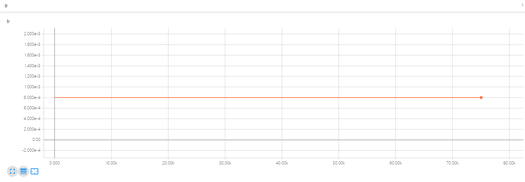
lr-学习率变化曲线
-
pareto-帕累托前沿图
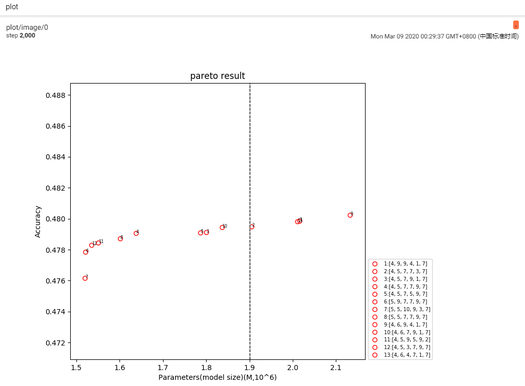
帕累托图横坐标为模型大小或计算量即约束项,纵坐标为结构搜索后的精度。图中的精度为搜索过程的评估结果,如果要获得更好的精度,建议对搜索结构进行充分训练。
搜索模型结构具有不同的精度、参数量/计算量/时延,开发者可根据实际需求选择合适的模型。
搜索结果展示
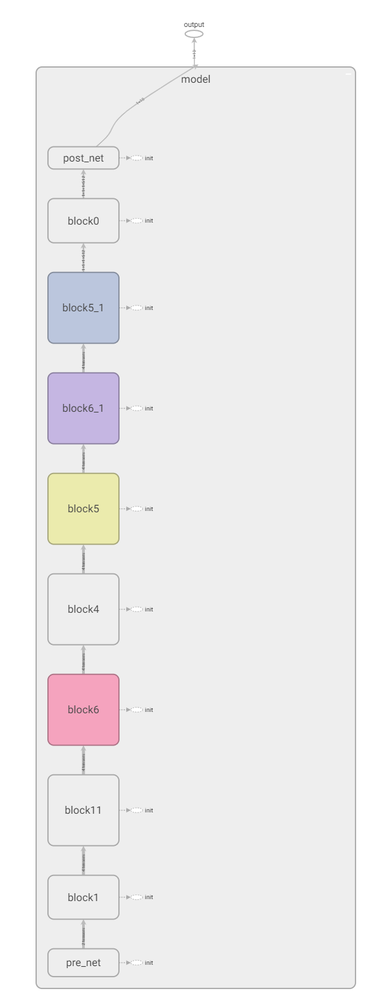
搜索结束后,工具会自动将pareto图中模型结构保存在results目录,生成多个model_arch_result_$NUM.py文件。其中$NUM文件编号与pareto图上的编号一致,头部有model_param_size和accuracy,开发者可根据TensorBoard中的pareto图或者这两个参数选择合适的网络结构,例如TensorFlow版本的搜索结果(PyTorch版本的搜索结果只是实现框架不同,不再赘述)如下图所示:
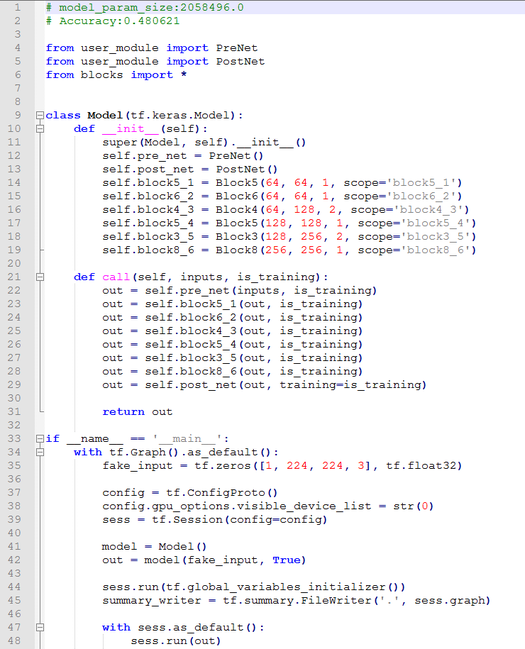
开发者选定合适的模型结构文件,可以拷贝到results的上一级目录,并执行模型结构文件。
python3 model_arch_result_$NUM.py
执行结束后,当前目录下会生成模型的pb文件和TensorBoard日志文件,开发者可通过TensorBoard查看模型的图结构。如下: