LLM模型一站式量化
简介
本工具提供大语言模型(Large Language Model,以下简称LLM)的4bit低位量化能力,采用标准的三段式量化流程:权重量化、激活量化和量化参数提取。三段式量化流程说明如下表所示。
表1 大语言模型4bit低位量化三阶段流程
| 阶段 | 输入 | 输出 |
|---|---|---|
| 阶段一(权重量化) | - 开发者提供 - JSON数据集(text字段作为prompt) - HuggingFace模型路径(开发者浮点模型) - 量化配置及执行文件 - config.yaml - run.sh | - dopt_config.json:开发者需完成该文件的量化策略配置后,重新执行此阶段 - trained_quant_weight.pth:权重量化参数 说明: 开发者需根据阶段一生成的dopt_config.json文件手动进行量化策略配置后,再次执行该阶段。 |
| 阶段二(激活量化) | - 开发者提供 - JSON数据集(text字段作为prompt) - HuggingFace模型路径(开发者浮点模型) - 量化配置及执行文件 - config.yaml - run.sh | trained.pth:用于阶段三加载或量化仿真验证 |
| 阶段三(量化参数提取) | - 开发者提供 - JSON数据集(text字段作为prompt) - HuggingFace模型路径(开发者浮点模型) - 量化配置及执行文件 - config.yaml - run.sh | - fake_quant_weight.pth:用于ONNX模型导出 - quant_params_file:权重及激活量化参数 |
量化前准备工作
- HuggingFace浮点模型
- JSON格式数据集,使用“text”字段作为prompt关键字
- 量化配置文件config.yaml
- run.sh执行脚本
![]()
- LLM在量化过程中使用AutoModelForCausalLM以及AutoTokenizer加载,所以开发者的HuggingFace浮点模型需要满足该加载方式约束。
- run.sh执行脚本环境须与开发者推理或者训练环境保持一致,否则模型加载或推理失败。
config.yaml示例
config.yaml用于模型量化配置,开发者可根据实际需要进行配置。以下示例可供参考,主要参数说明请参见config.yaml配置参数说明。
kd:
enable: False
loss: mse
micro_batch_size: 2
gradient_accumulation_steps: 4
weight_decay: 0.0
warmup_steps: 10
num_epochs: 3
learning_rate: !!float 1e-4
eval_step: 1
logging_step: 50
lr_scheduler_type: cosine
trainable_keys:
- quant_alpha
- norm
no_split_module_classes:
- Qwen2DecoderLayer
- GlmDecoderLayer
- LlamaDecoderLayer
- HunYuanDecoderLayer
dataset:
train_files: dataset.json
train_samples: 1024
ptq_samples: 1024
extra_training_config:
fp16: True
cutoff_len: 128
num_samples: 256
quant_param_2: False
embedding_separate: True
lm_head_size:
config.yaml配置参数说明
以下为config.yaml文件的关键配置参数,具体说明如下表所示。
| 参数 | 参数 | 默认取值 | 说明 |
|---|---|---|---|
| kd:量化蒸馏相关 | enable | False | - True:使用蒸馏量化策略 - False:使用无训练量化策略,速度快,效果较稳定 |
| kd:量化蒸馏相关 | loss | mse | 量化蒸馏损失函数,仅支持mse |
| kd:量化蒸馏相关 | micro_batch_size | 2 | 单卡batch |
| kd:量化蒸馏相关 | gradient_accumulation_steps | 4 | 梯度累计步数 |
| kd:量化蒸馏相关 | weight_decay | 0.0 | 权重衰减系数 |
| kd:量化蒸馏相关 | warmup_steps | 10 | 预热步数 |
| kd:量化蒸馏相关 | num_epochs | 3 | 训练迭代次数 |
| kd:量化蒸馏相关 | learning_rate | 1e-4 | 学习率 |
| kd:量化蒸馏相关 | logging_step | 50 | log打印步数 |
| kd:量化蒸馏相关 | lr_scheduler_type | cosine | 学习率调整策略。 |
| kd:量化蒸馏相关 | trainable_keys | - | 配置可训练参数。 - quant_alpha:量化层的可训练参数 - norm:layer_norm层的可训练参数 |
| kd:量化蒸馏相关 | no_split_module_classes | - | 多卡切分时,选择切分粒度。 - Qwen2DecoderLayer - GlmDecoderLayer - LlamaDecoderLayer - HunYuanDecoderLayer |
| dataset | train_files | - | JSON格式训练数据文件,dataset.json |
| dataset | train_samples | 1024 | kd使能为True时, 训练集样本数,缺省默认全量数据集 |
| dataset | ptq_samples | 1024 | PTQ优化样本数,缺省默认全量数据集 |
| dataset | extra_training_config | fp16 | 训练数据类型,仅支持fp16 |
| dataset | cutoff_len | 128 | 激活量化样本序列长度。 |
| dataset | num_samples | 256 | 激活量化校准样本数 |
| dataset | quant_param_2 | False | - True:Kirin9020 - False:KirinX90 |
| dataset | embedding_separate | True | - True:单独保存为bin文件 - False: 导出embedding的量化参数到量化文件,合并形态。 |
| dataset | lm_head_size: | - | 可指定lmhead长度,硬件对齐。 |
执行三段式量化
按以下步骤执行run.sh文件,stagex为传入参数,具体可参考run.sh示例。
-
权重量化。
-
选配量化策略。
生成插件式量化配置文件dopt_config.json。
bash run.sh stage1量化策略可选配置为:
Quant_act_weight_eco decode层策略Quant_lm_head lm_head层策略Quant_Embed_MinMax embedding层策略 -
进行权重量化。
bash run.sh stage1
-
-
激活量化。
bash run.sh stage2 -
提取量化参数。
bash run.sh stage3
run.sh示例
#!/bin/bash
set -e
qlibs='path/to/dopt_pytorch_py3'
export WANDB_DISABLED=true
export HF_DATASETS_OFFLINE=0
export PYTHONPATH=${qlibs}:$PYTHONPATH
# 设置为cuda或npu模式,二选一
# cuda模式
export DEVICE=cuda
export CUDA_VISIBLE_DEVICES=1
# npu模式
# export DEVICE=npu
# export ASCEND_RT_VISIBLE_DEVICES=2,3
ROOT=.
testcase='output_dir'
RUN_FILE=${qlibs}/dopt/dopt_lm/opt_main.py
output_dir=${ROOT}/${testcase}/train_output
mkdir -p ${output_dir}
cp ${ROOT}/config.yaml $output_dir
model_path='path/to/model'
dopt_config=./${testcase}/dopt_config.json
quant_stage=$1
block_size=128
python -u \
${RUN_FILE} --model-path $model_path \
--dopt-config $dopt_config \
--optimize-config ${ROOT}/config.yaml \
--quant-stage $quant_stage \
--block-size $block_size \
--output-dir ${output_dir} 2>&1 | tee ${output_dir}/logs.log
dopt_config.json量化配置文件说明
工具支持开发者插件式自定义LLM量化规格:
- 逐层权重量化位宽(bit)和分组大小(group_size)。
- 逐层激活量化位宽(bit)。
- 量化策略:decoder层使用"Quant_act_weight_eco",lm_head层使用"Quant_lm_head",embedding层使用"Quant_Embed_MinMax"。
{
"layer_strategy": {
"model.layers.0.self_attn.q_proj": {
"type": "<class 'torch.nn.modules.linear.Linear'>",
"quant_strategy": "Quant_act_weight_eco",
"weight":{
"bit": 4,
"group_size": 64
}
"input":{
"bit": 16
}
}
}
}
量化工具输出件
trained.pth ### 量化仿真可使用该文件
fake_quant_weight.pth ### 导出onnx文件使用该权重
trained_quant_weight.pth ### 阶段一的输出,阶段二的输入
量化仿真
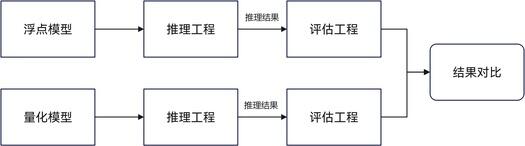
量化完成后,开发者可进行量化仿真推理,通过对比量化模型与原始浮点模型的输出结果,来评估量化模型精度是否满足要求。量化仿真推理工程可参考qwen2模型量化仿真推理demo。
插件方法
浮点模型完成加载和初始化后,使用以下接口将浮点模型转换为量化模型,模型推理逻辑不变,可参考qwen2模型量化仿真推理demo。
import sys
sys.path.append("path/to/dopt")
def get_quanted_model(base_model, dopt_config, quanted_ckpt):
from dopt.dopt_lm.do_opt import(
optimize_model,
set_quant_state,
set_calibrate_state,
set_run_mode,
)
model = optimize_model(base_model, dopt_config)
model.load_state_dict(torch.load(quanted_ckpt, map_location=torch.device('cpu')), strict=True)
set_quant_state(model, weight_state=True, input_state=True)
set_calibrate_state(model, False)
model.eval()
return model
- base_model:开发者浮点模型(使用transformers库AutoModelForCausalLM类进行加载)。
- dopt_config:量化配置文件。
- quanted_ckpt:量化后pth文件。
qwen2模型量化仿真推理demo
import os
import sys
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
sys.path.append('path/to/dopt')
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def get_quanted_model(base_model, dopt_config, quanted_ckpt):
"""
加载量化模型核心函数
:param base_model: 原始HF模型对象
:param dopt_config: 量化配置文件路径(dopt_config.json)
:param quanted_ckpt: 量化权重路径(trained.pth)
:return: 量化后的模型
"""
from dopt.dopt_lm.do_opt import(
optimize_model,
set_quant_state,
set_calibrate_state,
set_run_mode,
)
# 模型量化优化(根据配置文件应用4bit量化策略)
model = optimize_model(base_model, dopt_config)
# 加载量化权重(强制CPU加载避免显存冲突)
model.load_state_dict(torch.load(quanted_ckpt, map_location=torch.device('cpu')), strict=True)
# 设置量化状态
set_quant_state(model, weight_state=True, input_state=True) # 启用权重和激活量化
set_calibrate_state(model, False) # 关闭校准模式
model.eval()
return model
def generate(prompt = "Give me a short introduction to large language model."):
"""
量化模型推理函数
:param prompt: 输入文本(默认示例prompt)
:return: 模型生成的响应
"""
# 构建Qwen2专用对话模板
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud..."},
{"role": "user", "content": prompt}
]
# 应用模板并tokenize
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 执行生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512, # 控制最大生成长度
)
# 后处理:去除输入部分
generated_ids = [
output_ids[len(input_ids):]
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
return tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
if __name__ == '__main__':
# === 1. 加载原始模型 ===
model_name = "path/to/model" # 需替换为实际模型路径
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16, # 半精度加载
device_map="auto" # 自动分配GPU
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# === 2. 加载量化模型 ===
quant_res_root = 'dsr1_qwen7b_ptq' # 量化结果目录
dopt_config = f"./{quant_res_root}/dopt_config.json" # 阶段一生成的配置文件
quanted_ckpt = f"./{quant_res_root}/train_output/trained.pth" # 阶段二生成的权重
model = get_quanted_model(
model,
dopt_config, # 需确保已正确配置量化参数
quanted_ckpt # 需与当前模型架构匹配
)
# === 3. 执行推理测试 ===
prompt = "who are you?"
response = generate(prompt)
print("量化模型推理结果:", response)
"""
预期输出示例:
"Hi, I am Qwen, ..."
"""