SoftmaxFlashV2
功能说明
将输入tensor[m0, m1, ...mt, n](t大于等于0)的非尾轴长度相乘的结果看作m,则输入tensor的shape看作[m, n]。对输入tensor[m,n]按行做如下计算,不同的update值对应不同的计算公式,其中x、inmax和insum为输入,M、S、E均为输出。
-
update为false:
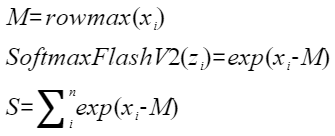
-
update为true:
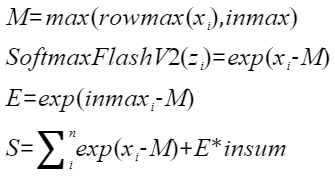
当输入shape为ND格式时,内部的reduce过程按last轴进行。当输入shape为NZ格式时,内部的reduce过程按照last轴和first轴进行
实现原理
计算过程根据isUpdate是否使能分为两个分支处理,均在Vector上进行。
-
当isUpdate为false时,分为如下几步:
- reducemax步骤:对输入x的每一行数据求最大值得到[m, 1],计算结果会保存到一个临时空间temp中。
- broadcast步骤:对temp中的数据[m, 1]做一个按datablock为单位的填充,比如float类型下,把[m, 1]扩展成[m, 8],同时输出max。
- sub步骤:对输入x的所有数据按行减去max。
- exp步骤:对sub之后的所有数据求exp,并且输出y。
- reducesum步骤:对exp结果的每一行数据求和得到[m, 1],计算结果会保存到临时空间temp中。
- broadcast步骤:对temp[m, 1]做一个按datablock为单位的填充,比如float类型下,把[m, 1]扩展成[m, 8],同时输出sum。
-
当isUpdate为true时,分为如下几步:
- reducemax步骤:对输入x的每一行数据求最大值得到[m, 1],计算结果会保存到一个临时空间temp中。
- broadcast步骤:对temp中的数据[m, 1]做一个按datablock为单位的填充,比如float类型下,把[m, 1]扩展成[m, 8],保存为max。
- max步骤:对输入inmax和上一步计算的max做max操作,得到新的max并输出。
- sub步骤:将输入inmax和新的max相减,然后做exp,计算得到expmax并输出。
- sub步骤:将输入x和新的max按行相减。
- exp步骤:对sub之后的所有数据求exp,并且输出y。
- reducesum步骤:对exp结果的每一行数据求和得到[m, 1],计算结果会保存到临时空间temp中。
- broadcast步骤:对temp数据[m, 1]做一个按datablock为单位的填充,比如float类型下,把[m, 1]扩展成[m, 8],保存到sum中。
- mul步骤:将输入insum和expmax结果相乘。
- add步骤:将相乘结果和sum相加,保存到sum并输出。
函数原型
高阶API接口
template <typename T, bool isUpdate = false, bool isReuseSource = false, bool isBasicBlock = false, bool isDataFormatNZ = false, const SoftmaxConfig& config = SOFTMAX_DEFAULT_CFG> __aicore__ inline void SoftmaxFlashV2(const LocalTensor<T>& dstTensor, const LocalTensor<T>& expSumTensor, const LocalTensor<T>& maxTensor, const LocalTensor<T>& srcTensor, const LocalTensor<T>& expMaxTensor, const LocalTensor<T>& inExpSumTensor, const LocalTensor<T>& inMaxTensor, const SoftMaxTiling& tiling, const SoftMaxShapeInfo& softmaxShapeInfo = {})
tiling获取接口
__aicore__ inline constexpr SoftMaxTiling SoftMaxFlashV2TilingFunc(const SoftMaxShapeInfo& shapeInfo, const uint32_t dataTypeSize1, const uint32_t dataTypeSize2, const uint32_t localWorkSpaceSize, const bool isUpdate = false, const bool isBasicBlock = false, const bool isDataFormatNZ = false, const bool isFlashOutputBrc = false)
参数说明
表1 模板参数说明
| 参数名 | 描述 |
|---|---|
| T | 操作数的数据类型。支持的数据类型为:half、float。 |
| isUpdate | 是否使能update部分中的计算。 |
| isReuseSource | 预留参数,暂未启用,为后续的功能扩展做保留,必须使用默认值,默认值为false。 |
| isBasicBlock | 该参数为预留参数,只支持false。 |
| isDataFormatNZ | 数据格式支持ND和NZ,默认取值为false,为ND格式。 |
| config | 是否需要检查shape和tiling的一致性;若不一致,API内会根据shape重新计算所需tiling。isCheckTiling默认取值true:API内部会检查一致性 |
表2 高阶API接口参数说明
| 参数名 | 输入/输出 | 描述 |
|---|---|---|
| dstTensor | 输出 | 目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 dstTensor的shape和源操作数srcTensor一致。 |
| expSumTensor | 输出 | 目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 用于保存softmax计算过程中reducesum的结果。 expSumTensor的last轴长度固定为32Byte,即一个datablock长度。该datablock中的所有数据为同一个值,比如half数据类型下,该datablock中的16个数均为相同的reducesum的值。 非last轴的长度与dstTensor保持一致。 |
| maxTensor | 输出 | 目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 用于保存softmax计算过程中reducemax的结果。 maxTensor的last轴长度固定为32Byte,即一个datablock长度。该datablock中的所有数据为同一个值。比如half数据类型下,该datablock中的16个数均为相同的reducemax的值。 非last轴的长度与dstTensor保持一致。 |
| srcTensor | 输入 | 源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 last轴长度需要32Byte对齐。 |
| expMaxTensor | 输出 | 目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 expMaxTensor的last轴长度固定为32Byte,即一个datablock长度。该datablock中的所有数据为同一个值,比如half数据类型下,该datablock中的16个数均为相同的值。 非last轴的长度需要与dstTensor保持一致。 |
| inExpSumTensor | 输入 | 源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 softmax计算所需要的sum值。 inExpSumTensor的last轴长度固定为32Byte,即一个datablock长度。该datablock中的所有数据为同一个值,比如half数据类型下,该datablock中的16个数均为相同的值。 非last轴的长度需要与dstTensor保持一致。 |
| inMaxTensor | 输入 | 源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 softmax计算所需要的max值。 除模板参数config配置为非拓展模式(SoftmaxMode::SOFTMAX_OUTPUT_WITHOUT_BRC)的场景外,inMaxTensor的last轴长度固定为32Byte,即一个datablock长度。该datablock中的所有数据为同一个值,比如half数据类型下,该datablock里的16个数均为相同的值。 非last轴的长度需要与dstTensor保持一致。 |
| tiling | 输入 | softmaxflashv2接口计算所需tiling信息。通过SoftMaxFlashV2TilingFunc获取。 |
| softmaxShapeInfo | 输入 | srcTensor的shape信息。SoftMaxShapeInfo类型,具体定义如下: - uint32_t srcM:非尾轴长度的乘积 - uint32_t srcK:尾轴长度,必须32Byte对齐 - uint32_t oriSrcM:原始非尾轴长度的乘积 - uint32_t oriSrcK:原始尾轴长度 |
表3 SoftMaxFlashV2TilingFunc接口参数说明
| 参数名 | 输入/输出 | 描述 |
|---|---|---|
| srcShape | 输入 | 输入srcTensor的shape信息。 |
| localWorkSpaceSize | 输入 | 剩余的可供SoftmaxFlashV2接口计算的空间大小。目前不需要。 |
| dataTypeSize1 | 输入 | 计算的源数据的数据类型,比如half=2。 |
| dataTypeSize2 | 输入 | 参与计算的maxTensor和sumTensor的数据类型,比如half=2。 |
| isUpdate | 输入 | 是否使能刷新功能,和kernel侧SoftmaxFlashV2接口一致。 |
| isBasicBlock | 输入 | 是否要使能基本块计算。只支持false。 |
| isFlashOutputBrc | 输入 | 是否使能输出shape的非拓展模式。建议设置为false或使用默认值 |
| softmaxFlashTiling | 输出 | 输出SoftmaxFlashV2接口所需的tiling信息。 |
返回值
无
支持的型号
Kirin9020系列处理器
KirinX90系列处理器
约束说明
- srcTensor和dstTensor的Tensor的空间可以复用,maxTensor和inMaxTensor的空间可以复用,expSumTensor和inExpSumTensor的空间可以复用。
- 除模板参数config配置为非拓展模式(SoftmaxMode::SOFTMAX_OUTPUT_WITHOUT_BRC)的场景外,expSumTensor、maxTensor、expMaxTensor、inExpSumTensor、inMaxTensor的Tensor空间,last轴长度必须固定32Byte。
- 操作数地址偏移对齐要求请参见通用约束。
- 输入输出操作数参与计算的数据长度要求32B对齐。
调用示例
// 其它处理省略
__aicore__ inline void Compute()
{
AscendC::LocalTensor<half> xLocal = queueX.DeQue<half>();
AscendC::SoftMaxShapeInfo srcShape = { M_VALUE, K_VALUE, M_VALUE, K_VALUE };
AscendC::SoftmaxFlashV2<half, false, false, false, false>(xLocal, sumLocal, maxLocal, xLocal, expmaxLocal, sumLocal,
maxLocal, softmaxTiling, srcShape);
AscendC::DataCopy(zGm[0], xLocal, xLength);
queueX.FreeTensor(xLocal);
}