矩阵计算
KirinX90/Kirin9030处理器不支持结构化稀疏功能,并且Mmad左矩阵分形结构在Kirin9030有差异。
表1 矩阵计算兼容说明
| 基础API | 兼容说明 |
|---|---|
| MmadWithSparse | 不支持。不支持结构化稀疏功能,因此算子需要采用正常稠密的矩阵计算。 |
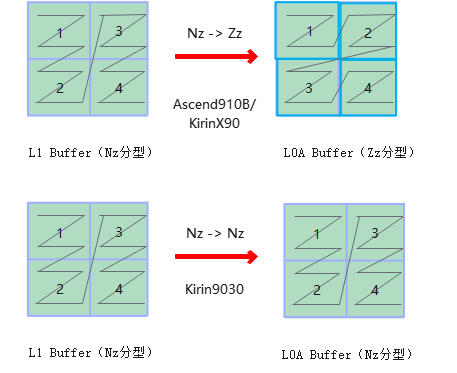
| Mmad | Kirin9030芯片平台,L0A Buffer分形改变,从ZZ(Ascend910B/Ascend910C/KirinX90)转换为ZN格式。算子做LoadData时,需要做LoadData参数修改适配,详见下图。 |
Mmad左矩阵分形格式变换修改适配方案:
// 示例代码
__aicore__ inline void SplitA()
{
int srcOffset = 0;
int dstOffset = 0;
AscendC::LocalTensor<half> a1Local = inQueueA1.DeQue<half>();
AscendC::LocalTensor<half> a2Local = inQueueA2.AllocTensor<half>();
#if defined(__NPU_ARCH__) && (__NPU_ARCH__ == 2201 || __NPU_ARCH__ == 3003)
// Ascend910B、Ascend910C和KirinX90,LoadData时做Nz2Zz的分形转换
for (int i = 0; i < mBlocks; ++i) {
AscendC::LoadData2DParams loadDataParams;
// kBlocks表示列方向上有几个宽为16的half类型矩阵
loadDataParams.repeatTimes = kBlocks;
// mBlocks表示行方向上有几个高为16的half类型矩阵
loadDataParams.srcStride = mBlocks;
loadDataParams.ifTranspose = false;
AscendC::LoadData(a2Local[dstOffset], a1Local[srcOffset], loadDataParams);
srcOffset += 16 * 16;
dstOffset += k * 16;
}
#endif
#if defined(__NPU_ARCH__) && (__NPU_ARCH__ == 3113)
// Kirin9030,LoadData时不需要做Nz2Zz的分形转换,对应搬运参数需要修改
AscendC::LoadData2DParams loadDataParams;
loadDataParams.repeatTimes = m * k / 512; // 小z矩阵的个数
loadDataParams.srcStride = 1; // 小z矩阵之间的间隔
loadDataParams.dstGap = 0;
loadDataParams.ifTranspose = false;
AscendC::LoadData(a2Local, a1Local, loadDataParams);
inQueueA2.EnQue<half>(a2Local);
inQueueA1.FreeTensor(a1Local);
#endif
}