毕昇编译器
毕昇编译器简介
毕昇编译器是基于LLVM开源软件开发的一款用于C/C++等语言的native编译器,能将C/C++代码工程编译链接成可以在设备上运行的二进制。在无需改动用户代码的条件下,相比业界主流的开源LLVM或GCC编译器,毕昇编译器能提供更强大的优化能力,使编译链接出来的二进制的运行时长更短、指令数更少,帮助提升应用在设备上的运行流畅度。
能力范围
毕昇编译器提供将C/C++代码工程编译链接成可以在设备上运行的二进制的基本能力,主要包括以下三方面:
- 编译能力:将C/C++源码文件编译成汇编文件,汇编文件是指使用汇编语言编写的文件。
- 汇编能力:将汇编文件汇编成可重定向文件,可重定向文件是ELF格式的二进制文件,但不能直接放在设备上运行。
- 链接能力:将一个或多个可重定向文件一起链接成一个可执行的二进制文件。
亮点特征示例
毕昇编译器相对于LLVM/GCC编译器有以下特点。
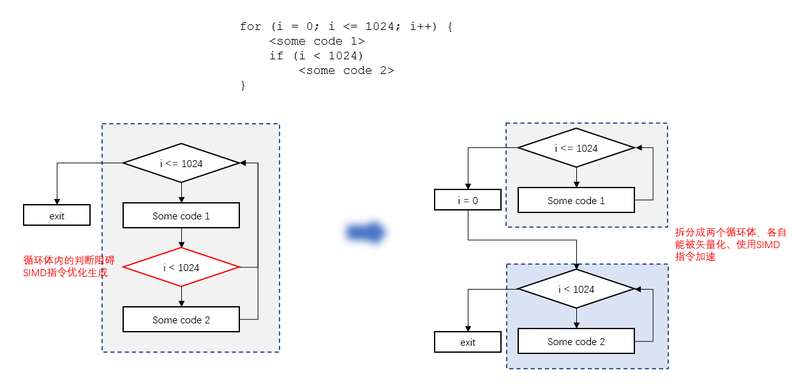
- 毕昇编译器Loop Distribution优化增强示例
针对循环相关的编译优化,毕昇编译器在场景识别、结构变换等方面做了改进和增强。例如在社区LLVM已有的Loop Distribution优化上,毕昇编译器相比开源LLVM编译器,能额外识别出循环内不同代码块间数据依赖关系、以及不同代码块运行的迭代次数差别,从而能对更多的循环进行loop distribution优化。
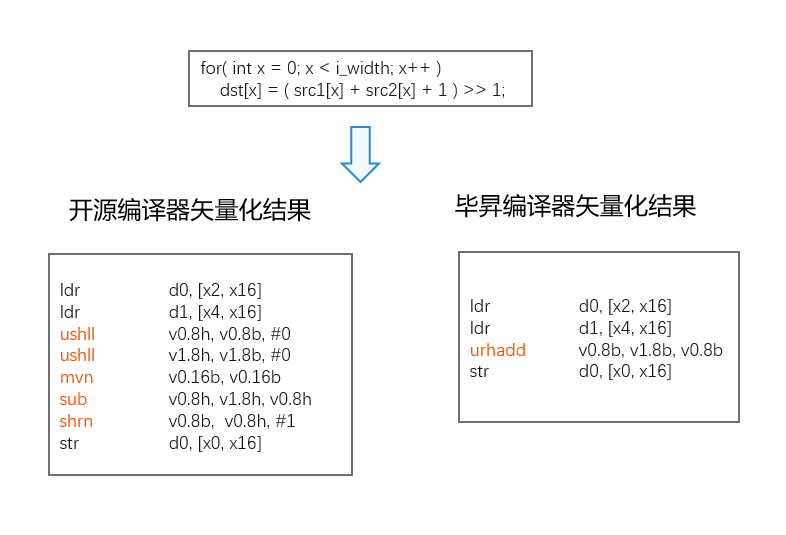
- 毕昇编译器矢量化优化增强示例
毕昇编译器在矢量化优化方面,相比开源LLVM编译器,不仅能将更多的循环做矢量化转换,还在矢量化指令选择上更高效。例如下面示例中,开源LLVM编译器虽然做了矢量化,但使用了5条矢量指令;而毕昇编译器只需要使用2条矢量指令,最终产生的二进制效率更优。
毕昇编译器使用指导
在DevEco Studio 中使用毕昇编译器:
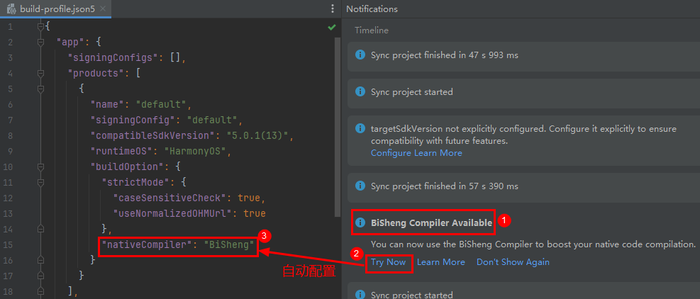
- 开发者获取或在线升级到DevEco Studio 5.1.1 release及之后的版本,新建C/C++工程默认使用毕昇编译器,打开C/C++老工程有弹窗提示,点击Try Now可以切换使用毕昇编译器,构建HarmonyOS工程的C/C++代码。
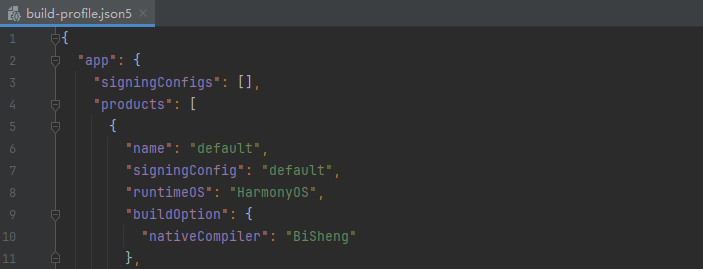
- 开发者获取DevEco Studio 5.1.1 beta及之前的版本,默认使用还是开源llvm编译器,需要在HarmonyOS应用的工程级build-profile.json5中简单配置即可使用毕昇编译器:在runtimeOS为HarmonyOS的时候,设置nativeCompiler为BiSheng,即可使用毕昇编译器构建HarmonyOS工程的C/C++代码。
此外,当开发者自己单独配置流水线切换毕昇编译器时,可能会遇到“找不到头文件”错误,此时添加sysroot路径选项即可解决(xxx为sdk的路径):
--sysroot=xxx/sdk/default/openharmony/native/sysroot
在流水线中使用毕昇编译器:
若在流水线中直接使用SDK构建,不通过DevEco构建,可以使用下述方式使用毕昇编译器:
- 找到毕昇编译器所在路径:
在DevEco的安装目录下,会有hms和HarmonyOS两个目录:
毕昇编译器所在的路径为:xxx/sdk/default/hms/native/BiSheng。
- 替换毕昇编译器
替换编译器有2种方式,命令替换和目录替换。
(1)命令替换:
如果脚本中有指定使用的编译器路径,如TOOLCHAIN_PATH="xxx/sdk/default/openharmony/native/llvm/bin/clang",则可以直接将其替换为"xxx/sdk/default/hms/native/BiSheng/bin/clang"。
注意:若编译器路径为拼凑路径,且会影响到sysroot的路径,要确保sysroot路径仍指向HarmonyOS下的sysroot。
(2)目录替换:
该方法最为简单,不需要改动任何脚本或者环境变量,只需要将目录做一次拷贝,步骤如下:
1) 将xxx/sdk/default/openharmony/native下的llvm重命名为 llvm-bak(以便后续恢复,也可直接删除);
2) 拷贝xxx/sdk/default/hms/native/BiSheng 文件夹到 xxx/sdk/default/openharmony/native目录下;
3) 将BiSheng重命名为llvm。
做完上述步骤,重启流水线即可用毕昇编译器构建。
主要编译优化特性
- IClang
IClang是一种增量编译优化手段。该特性在增量编译的基础上,进一步实现函数级别的编译复用,利用上一次的编译结果,显著提升编译速度。
1. 启用指导
编译时,需要增加-iclang选项。以CMake构建系统为例,可在 CMakeLists.txt 中配置:add_compile_options(-iclang)
2. IClang维护的数据
IClang 会在目标文件所在目录下自动生成一个 .iclang 子目录,用于存储其运行所需的数据。例如,编译 test.o 时,会创建 test.o.iclang 目录。
3. IClang的编译模式
由于用户通常仅修改部分源文件而非整个项目,故IClang仅会为需要频繁修改的源文件生成可复用的缓存。具体而言,IClang的编译可以分为以下三种模式:
(1)初始模式:在首次编译-iclang时,仅维护一些非常轻量的元数据,从而避免对用户的全量编译性能造成影响。
(2)预热模式:当用户首次对某个文件进行修改并重新编译时,IClang会认定其为高频修改目标,并执行一些必要的分析与缓存构建。该模式可能会略微影响用户的首次增量编译性能,相关产物存储在.iclang中。
(3)增量编译模式:完成预热后的文件,用户后续对其修改之后的增量编译都可以得到加速,非常适用于频繁修改某个源文件的场景。
4. 缓存失效的情况
(1)上次编译生成的二进制产物被删除。此时IClang将无法实现二进制函数复用,因此回退到初始模式。
(2)头文件内容或配置发生变化。此时IClang将无法判断哪些函数可以被安全复用,因此回退到初始模式。
(3)编译命令发生变化。此时构建系统会重新编译整个项目,IClang保持与构建系统的行为一致,回退到初始模式。
当IClang发生内部错误时,会在相关产物下生成.iclangtmp目录,检测到该目录存在后IClang将进入恢复模式,完全退回到Clang,确保用户可以正常编译。同时,应将这一行为报告给IClang开发者进行确认和修复。如有需要,用户也可以尝试自行删除.iclangtmp目录,此时IClang将会重新回到初始模式。
5. 编译选项限制
(1)IClang仅会作用于-c编译,且命令只有一个输入文件和一个输出文件,常见的构建系统(如CMake)都可以满足这个条件。
(2)IClang目前仅支持-O0优化级别选项,用户需要注意仅在debug模式的开发环境下使用。如果检测到其他优化级别选项,IClang将回退到Clang并提示:[IClang Warning] Please ensure that IClang is only enabled under -O0。
(3)IClang不支持和-flto选项共同使用。
(4)为了确保二进制复用的正确进行,IClang会添加-ffunction-sections与-fdata-sections两个编译选项,按符号划分二进制文件的代码段和数据段。
6. 编译前端限制
IClang在优化过程中,出于正确性考虑会选择不对包含某些语法的函数进行优化,包括:数组实例化类型、函数指针实例化类型、虚函数、UniqueExternalLinkage。
7. 编译后端限制
IClang生成的二进制产物遵循X86-64 ELF规范,在此基础上额外提出以下限制:仅支持64位小端序;二进制文件中仅包含Rela重定位表,不支持Rel重定位表;链接器采用lld,不支持gnu ld。
- PGO(Profile Guided Optimization)
PGO是一种自适应优化手段。它通过收集代码在实际运行过程中的性能数据,来准确得知例如哪些函数是真正被频繁执行的、哪些分支是真正频繁进入的等信息,从而指导编译器做出相应优化。相较于传统的PGO,毕昇PGO具有更强的准确性和优化性。
毕昇编译器通过信号量触发文件写入操作:Dso在接受到特定信号量时将采样信息写入文件中,并清空相应计数器。 其主要流程如下图所示: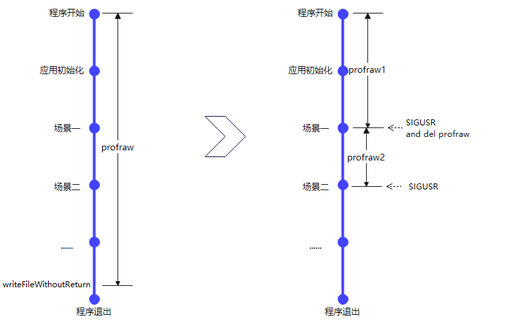
这种方案能够精准的控制采样范围,解决了传统PGO依赖业务中存在的统一入口和出口,无法对某一段范围进行精准采样的痛点。
毕昇PGO使用和开源LLVM一样,优化流程分为插桩阶段、采集阶段和优化阶段。
1. 插桩阶段
编译时,需要增加选项:-fprofile-generate=/data/storage/el2/base/files,该路径为沙箱路径,会在其映射路径下产生对应的文件,映射路径为:/data/app/el2/100/base/应用名/files。
可以通过检查编译后文件是否有llvm_prf字段或反汇编指令序列来判断是否插桩成功。
llvm-objdump -h xx.so # 检查是否有llvm_prf字段
llvm-objdump -d xx.so # 看反汇编是否有ldr add store代码序列
2. 采集阶段
通过lldb方式进行profile数据采集。
编译完成后,在Deveco中用debug模式推送APP包:
启动后会出现debug窗口,确保是Native的debug模式,未出现则需要修改Deveco的debug Type配置为Native。

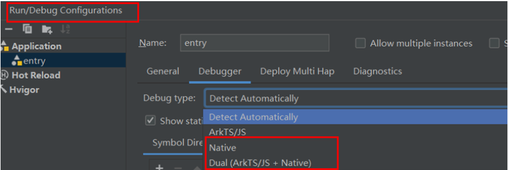
启动完成后,找到native debug的lldb位置,需要在lldb中设置参数,保证业务正常运行,不会在debug模式下被一些信号影响数据采集(信号一般是程序本身发送),设置方法为:

由于程序没有设置断点,导致程序暂停的原因是信号量,可以屏蔽信号量暂停机制:
查看有哪些信号量:
(lldb) process handle
屏蔽所有信号量暂停效果:
(lldb) process handle SIG* -s false
SIG*为信号量name, 若要一次性屏蔽所有信号量,则无需指定信号量名。
做完上述动作,直接发送信号量:
(lldb) process signal SIGUSR2
可以在对应的目录(/data/app/el2/100/base/应用进程名/files)找到default*_profile文件,每发送一次信号会产生一次文件。第一次发送采集到的数据为:应用启动到发送信号时间点的数据;第二次发送为:第一次发送信号量到第二次发送信号量期间的数据;以此类推。可以控制发送信号量时间,来采集我们需要场景的数据。 生成的文件没有权限删除,一次应用启动采集到的数据,是同名的,多次生成文件会覆盖,也可以保证采集的数据是目标场景的数据。
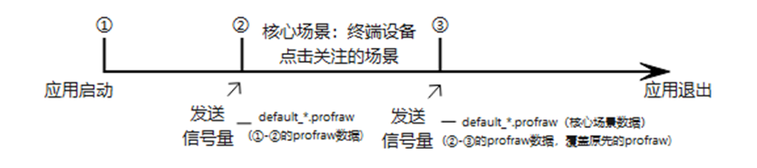
用hdc将该文件从手机拷贝到电脑上,使用与clang同级目录下的llvm-profdata.exe工具,执行 llvm-profdata merge --output=lib.profdata default_*.profraw 得到lib.profdata。
3. 优化阶段
重新编译,增加编译选项-fprofile-use=lib.profdata, lib.profdata为合并后的配置文件。
- LTO(Link Time Optimization)
LTO是一种在链接阶段跨编译单元进行优化的编译器优化手段,旨在提升程序性能。毕昇LTO使用和开源LLVM一样,但是相比开源LLVM在指令预取、inline算法、thin lto funciton import 算法、plt-inline优化等做了增强优化,进一步提升了生成代码的执行效率。
1. 优化指导
为启用LTO,需在编译阶段添加 -flto 选项。以CMake构建系统为例,可在 CMakeLists.txt 中配置:add_compile_options(-flto)
2. 注意事项
-flto:默认为full模式,会显著增加编译时长,但性能会更优
-flto=thin:可修改为 thin lto 降低编译时长,但性能不及full lto,两者相对平衡
若构建时间还显著增加,指定并行任务数加速构建,-flto-jobs=xxx, xxx根据电脑核数设置
- fp优化
fp优化是一组控制浮点运算语义和行为的编译器选项,它用于控制浮点表达式中的运算顺序是否可以被重排或合并,从而达到更高的性能或更强的可预测性。毕昇编译器默认关闭该优化,如果浮点计算场景较多,可以打开该优化
1. 优化指导
在编译阶段加入 -ffp-contract=on 选项。以CMake构建系统为例,在 CMakeLists.txt 中配置:add_compile_options( -ffp-contract=on)